CUDA C/C++编程的学习 本文基于英伟达提供的线上自主学习课程
加速计算正在取代 CPU 计算,成为最佳计算做法。加速计算带来的层出不穷的突破性进展、对加速应用程序日益增长的需求、轻松编写加速计算的编程规范以及支持加速计算的硬件的不断改进,所有这一切都在推动计算方式必然会过渡到加速计算。
为 GPU 编写应用程序代码 以下是一个 .cu 文件(.cu 是 CUDA 加速程序的文件扩展名)。其中包含两个函数,第一个函数将在 CPU 上运行,第二个将在 GPU 上运行。请抽点时间找出这两个函数在定义方式和调用方式上的差异。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 void CPUFunction () printf ("This function is defined to run on the CPU.\n" );void GPUFunction () printf ("This function is defined to run on the GPU.\n" );int main () 1 , 1 >>>();
以下是一些需要特别注意的重要代码行,以及加速计算中使用的一些其他常用术语:
1 __global__ void GPUFunction()
__global__ 关键字表明以下函数将在 GPU 上运行并可全局 调用,而在此种情况下,则指由 CPU 或 GPU 调用。通常,我们将在 CPU 上执行的代码称为主机 代码,而将在 GPU 上运行的代码称为设备 代码。 注意返回类型为 void。使用 __global__ 关键字定义的函数需要返回 void 类型。 1 GPUFunction<<<1, 1>>>();
通常,当调用要在 GPU 上运行的函数时,我们将此种函数称为已启动 的核函数 。 启动核函数时,我们必须提供执行配置 ,即在向核函数传递任何预期参数之前使用 <<< ... >>> 语法完成的配置。 在宏观层面,程序员可通过执行配置为核函数启动指定线程层次结构 ,从而定义线程组(称为线程块 )的数量,以及要在每个线程块中执行的线程 数量。稍后将在本实验深入探讨执行配置,但现在请注意正在使用包含 1 线程(第二个配置参数)的 1 线程块(第一个执行配置参数)启动核函数。 1 cudaDeviceSynchronize();
与许多 C/C++ 代码不同,核函数启动方式为异步 :CPU 代码将继续执行而无需等待核函数完成启动 。 调用 CUDA 运行时提供的函数 cudaDeviceSynchronize 将导致主机 (CPU) 代码暂作等待,直至设备 (GPU) 代码执行完成,才能在 CPU 上恢复执行。 练习 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 #include <stdio.h> void helloCPU () printf ("Hello from the CPU.\n" );void helloGPU () printf ("Hello from the GPU.\n" );int main () 1 ,1 >>>();
以上是对 nvidia 所给例子01-hello-gpu.cu
从核函数定义中删除关键字 __global__。注意错误中的行号:您认为错误中的 \”configured\” 是什么意思?完成后,请替换 __global__。
报错 a host function call cannot be configured。
未声明关键字__global__,函数不可被<<<…>>>配置
移除执行配置:您对 \”configured\” 的理解是否仍旧合理?完成后,请替换执行配置。
报错 a __global__ function call must be configured。
启动核函数必须提供执行配置。
移除对 cudaDeviceSynchronize 的调用。在编译和运行代码之前,猜猜会发生什么情况,可以回顾一下核函数采取的是异步启动,且 cudaDeviceSynchronize 会使主机执行暂作等待,直至核函数执行完成后才会继续。完成后,请替换对 cudaDeviceSynchronize 的调用。
只打印 Hello from the CPU.
核函数异步启动,CPU 将继续执行而不会等待 GPU 执行完成
重构 01-hello-gpu.cu,以便 Hello from the GPU 在 Hello from the CPU 之前 打印。
将helloGPU<<<1,1>>>();及cudaDeviceSynchronize();移至 helloCPU()前,main()如下
1 2 3 helloGPU<<<1 ,1 >>>();
cudaDeviceSynchronize();必须调至 helloCPU 前,若只改动 helloGPU 打印结果顺序不会变。
重构 01-hello-gpu.cu,以便 Hello from the GPU 打印两次 ,一次是在 Hello from the CPU 之前 ,另一次是在 Hello from the CPU 之后 。
重构后 main 函数如下
1 2 3 4 5 helloGPU<<<1 ,1 >>>();1 ,1 >>>();
编译并运行加速后的 CUDA 代码 CUDA 平台附带 NVIDIA CUDA 编译器 nvcc,可以编译 CUDA 加速应用程序,其中包含主机和设备代码。
曾使用过 gcc 的用户会对 nvcc 感到非常熟悉。例如,编译 some-CUDA.cu 文件就很简单:
1 nvcc -arch=sm_70 -o out some-CUDA.cu -run
nvcc 是使用 nvcc 编译器的命令行命令。将 some-CUDA.cu 作为文件传递以进行编译。 o 标志用于指定编译程序的输出文件。arch 标志表示该文件必须编译为哪个架构 类型。本示例中,sm_70 将用于专门针对本实验运行的 Volta GPU 进行编译,但有意深究的用户可以参阅有关 arch 标志虚拟架构特性 和 GPU 特性 的文档。为方便起见,提供 run 标志将执行已成功编译的二进制文件。 启动并行运行的核函数 程序员可通过执行配置指定有关如何启动核函数以在多个 GPU 线程 中并行运行的详细信息。更准确地说,程序员可通过执行配置指定线程组(称为线程块 或简称为块 )数量以及其希望每个线程块所包含的线程数量。执行配置的语法如下:
启动核函数时,核函数代码由每个已配置的线程块中的每个线程执行 。
因此,如果假设已定义一个名为 someKernel 的核函数,则下列情况为真:
someKernel<<<1, 1>>() 配置为在具有单线程的单个线程块中运行后,将只运行一次。someKernel<<<1, 10>>() 配置为在具有 10 线程的单个线程块中运行后,将运行 10 次。someKernel<<<10, 1>>() 配置为在 10 个线程块(每个均具有单线程)中运行后,将运行 10 次。someKernel<<<10, 10>>() 配置为在 10 个线程块(每个均具有 10 线程)中运行后,将运行 100 次。线程和块的索引 每个线程在其线程块内部均会被分配一个索引,从 0 开始。此外,每个线程块也会被分配一个索引,并从 0 开始。正如线程组成线程块,线程块又会组成网格 ,而网格是 CUDA 线程层次结构中级别最高的实体。简言之,CUDA 核函数在由一个或多个线程块组成的网格中执行,且每个线程块中均包含相同数量的一个或多个线程。
gridDim.x:网格中的线程块数 blockIdx.x:网格中线程块的索引 blockDim.x:线程块中的线程数 threadIdx.x:块中线程的索引 CUDA 核函数可以访问能够识别如下两种索引的特殊变量:正在执行核函数的线程(位于线程块内)索引和线程所在的线程块(位于网格内)索引。这两种变量分别为 threadIdx.x 和 blockIdx.x。
加速 for 循环 1 2 3 4 5 int N = 2 <<20 ;for (int i = 0 ; i < N; ++i)printf ("%d\n" , i);
如要并行此循环,必须执行以下 2 个步骤:
必须编写完成循环的单次迭代 工作的核函数。 由于核函数与其他正在运行的核函数无关,因此执行配置必须使核函数执行正确的次数,例如循环迭代的次数。 练习:使用单个线程块加速 for 循环 01-single-block-loop.culoop 函数运行着一个“for 循环”并将连续打印 0 至 9 之间的所有数字。将 loop 函数重构为 CUDA 核函数,使其在启动后并行执行 N 次迭代。重构成功后,应仍能打印 0 至 9 之间的所有数字。
原代码:
1 2 3 4 5 6 7 8 9 10 11 #include <stdio.h> void loop (int N) for (int i=0 ; i<N ; i++)printf ("This is iteration number %d\n" ,i);int main () int N =10 ;
重构后:
1 2 3 4 5 6 7 8 9 10 11 #include <stdio.h> void loop () printf ("This is iteration number %d\n" ,threadIdx.x);int main () 1 ,10 >>>();
注:每个线程块内,thread.x 的输出顺序是有序的,而不同线程块间的输出是无序的。如下,输出是无序的。但是若改为 loop<<<10,2>>>();可以发现仅线程块输出结果间是无序的,同一线程块内线程输出结果是有序的。
1 2 3 4 5 6 7 8 9 10 11 #include <stdio.h> void loop () printf ("This is iteration number %d\n" ,blockIdx.x);int main () 10 ,1 >>>();
*查阅了一些资料,询问了老师之后,得知严格意义上线程块和线程的输出顺序是无法控制的,“并行本身其实就不应该控制先后顺序的,如果需要控制的话,那就说明这个任务不适合做矢量化了,因为他是顺序依赖的”,这里的线程输出有序,猜测是因为显示系统进行了后处理。*所以在实际使用中需要考虑使用线程块加速的适用性。
调整线程块的大小以实现更多的并行化 线程块包含的线程具有数量限制:确切地说是 1024 个。为增加加速应用程序中的并行量,我们必须要能在多个线程块之间进行协调。
CUDA 核函数可以访问给出块中线程数的特殊变量:blockDim.x。通过将此变量与 blockIdx.x 和 threadIdx.x 变量结合使用,并借助惯用表达式 threadIdx.x + blockIdx.x * blockDim.x 在包含多个线程的多个线程块之间组织并行执行,并行性将得以提升。以下是详细示例。
执行配置 <<<10, 10>>> 将启动共计拥有 100 个线程的网格,这些线程均包含在由 10 个线程组成的 10 个线程块中。因此,我们希望每个线程(0 至 99 之间)都能计算该线程的某个唯一索引。
如果线程块 blockIdx.x 等于 0,则 blockIdx.x * blockDim.x 为 0。向 0 添加可能的 threadIdx.x 值(0 至 9),之后便可在包含 100 个线程的网格内生成索引 0 至 9。 如果线程块 blockIdx.x 等于 1,则 blockIdx.x * blockDim.x 为 10。向 10 添加可能的 threadIdx.x 值(0 至 9),之后便可在包含 100 个线程的网格内生成索引 10 至 19。 分配将要在 GPU 和 CPU 上访问的内存 CUDA 的最新版本(版本 6 和更高版本)已能轻松分配可用于 CPU 主机和任意数量 GPU 设备的内存。尽管现今有许多适用于内存管理并可支持加速应用程序中最优性能的 中高级技术 ,但我们现在要介绍的基础 CUDA 内存管理技术不但能够支持远超 CPU 应用程序的卓越性能,而且几乎不会产生任何开发人员成本。
如要分配和释放内存,并获取可在主机和设备代码中引用的指针,请使用 cudaMallocManaged 和 cudaFree 取代对 malloc 和 free 的调用,如下例所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 int N = 2 <<20 ;size_t size = N * sizeof (int );int *a;int *)malloc (size);free (a);int N = 2 <<20 ;size_t size = N * sizeof (int );int *a;cudaMallocManaged (&a, size);cudaFree (a);
网格大小与工作量不匹配 可能会出现这样的情况,执行配置所创建的线程数无法匹配为实现并行循环所需的线程数。
一个常见的例子与希望选择的最佳线程块大小有关。例如,鉴于 GPU 的硬件特性,所含线程的数量为 32 的倍数的线程块是最理想的选择,因其具备性能上的优势。假设我们要启动一些线程块且每个线程块中均包含 256 个线程(32 的倍数),并需运行 1000 个并行任务(此处使用极小的数量以便于说明),则任何数量的线程块均无法在网格中精确生成 1000 个总线程,因为没有任何整数值在乘以 32 后可以恰好等于 1000。
这个问题可以通过以下方式轻松地解决:
编写执行配置,使其创建的线程数超过 执行分配工作所需的线程数。 将一个值作为参数传递到核函数 (N) 中,该值表示要处理的数据集总大小或完成工作所需的总线程数。 计算网格内的线程索引后(使用 threadIdx + blockIdx*blockDim),请检查该索引是否超过 N,并且只在不超过的情况下执行与核函数相关的工作。 以下是编写执行配置的惯用方法示例,适用于 N 和线程块中的线程数已知,但无法保证网格中的线程数和 N 之间完全匹配的情况。如此一来,便可确保网格中至少始终拥有 N 所需的线程数,且超出的线程数至多仅可相当于 1 个线程块的线程数量:
1 2 3 4 5 6 7 8 9 10 int N = 100000 ;size_t threads_per_block = 256 ;size_t number_of_blocks = (N + threads_per_block - 1 ) / threads_per_block;
由于上述执行配置致使网格中的线程数超过 N,因此需要注意 some_kernel 定义中的内容,以确保 some_kernel 在由其中一个 ”额外的” 线程执行时不会尝试访问超出范围的数据元素:
1 2 3 4 5 6 7 8 9 __global__ some_kernel (int N) int idx = threadIdx.x + blockIdx.x * blockDim.x;if (idx < N)
跨网格的循环 或出于选择,为了要创建具有超高性能的执行配置,或出于需要,一个网格中的线程数量可能会小于数据集的大小。请思考一下包含 1000 个元素的数组和包含 250 个线程的网格(此处使用极小的规模以便于说明)。此网格中的每个线程将需使用 4 次。如要实现此操作,一种常用方法便是在核函数中使用跨网格循环 。
在跨网格循环中,每个线程将在网格内使用 threadIdx + blockIdx*blockDim 计算自身唯一的索引,并对数组内该索引的元素执行相应运算,然后将网格中的线程数添加到索引并重复此操作,直至超出数组范围。例如,对于包含 500 个元素的数组和包含 250 个线程的网格,网格中索引为 20 的线程将执行如下操作:
对包含 500 个元素的数组的元素 20 执行相应运算 将其索引增加 250,使网格的大小达到 270 对包含 500 个元素的数组的元素 270 执行相应运算 将其索引增加 250,使网格的大小达到 520 由于 520 现已超出数组范围,因此线程将停止工作 CUDA 提供一个可给出网格中线程块数的特殊变量:gridDim.x。然后计算网格中的总线程数,即网格中的线程块数乘以每个线程块中的线程数:gridDim.x * blockDim.x。带着这样的想法来看看以下核函数中网格跨度循环的详细示例:
1 2 3 4 5 6 7 8 9 10 __global__ void kernel (int *a, int N) int indexWithinTheGrid = threadIdx.x + blockIdx.x * blockDim.x;int gridStride = gridDim.x * blockDim.x;for (int i = indexWithinTheGrid; i < N; i += gridStride)
错误处理 与在任何应用程序中一样,加速 CUDA 代码中的错误处理同样至关重要。即便不是大多数,也有许多 CUDA 函数(例如,内存管理函数 )会返回类型为 cudaError_t 的值,该值可用于检查调用函数时是否发生错误。以下是对调用 cudaMallocManaged 函数执行错误处理的示例: 1 2 3 4 5 6 7 cudaError_t err;cudaMallocManaged (&a, N) if (err != cudaSuccess) printf ("Error: %s\n" , cudaGetErrorString (err));
启动定义为返回 void 的核函数后,将不会返回类型为 cudaError_t 的值。为检查启动核函数时是否发生错误(例如,如果启动配置错误),CUDA 提供 cudaGetLastError 函数,该函数会返回类型为 cudaError_t 的值。 1 2 3 4 5 6 7 8 9 10 11 12 13 1 , -1 >>>(); cudaGetLastError (); if (err != cudaSuccess)printf ("Error: %s\n" , cudaGetErrorString (err));
最后,为捕捉异步错误(例如,在异步核函数执行期间),请务必检查后续同步 CUDA 运行时 API 调用所返回的状态(例如 cudaDeviceSynchronize);如果之前启动的其中一个核函数失败,则将返回错误。 1 2 3 4 5 6 7 cudaError_t err;if (err != cudaSuccess) printf ("Error: %s\n" , cudaGetErrorString(err));
CUDA 错误处理功能 创建一个包装 CUDA 函数调用的宏对于检查错误十分有用。以下是一个宏示例,您可以在余下练习中随时使用:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 #include <stdio.h> #include <assert.h> inline cudaError_t checkCuda (cudaError_t result) if (result != cudaSuccess) {fprintf (stderr, "CUDA Runtime Error: %s\n" , cudaGetErrorString (result));assert (result == cudaSuccess);return result;int main () checkCuda ( cudaDeviceSynchronize () )
2 维和 3 维的网格和块 可以将网格和线程块定义为最多具有 3 个维度。使用多个维度定义网格和线程块绝不会对其性能造成任何影响,但这在处理具有多个维度的数据时可能非常有用,例如 2D 矩阵。如要定义二维或三维网格或线程块,可以使用 CUDA 的 dim3 类型,即如下所示:
1 2 3 dim3 threads_per_block (16 , 16 , 1 ) ;dim3 number_of_blocks (16 , 16 , 1 ) ;
鉴于以上示例,someKernel 内部的变量 gridDim.x、gridDim.y、blockDim.x 和 blockDim.y 均将等于 16。
此处介绍一个万能的索引计算式
1 2 3 4 5 6 7 8 9 10 11 12 int tid = blockIdx.z * (gridDim.x * gridDim.y) * (blockDim.x * blockDim.y * blockDim.z)\
使用 CUDA C/C++ 统一内存和 Nsight Systems (nsys) 管理加速应用程序内存 学习目标 当您在本实验完成学习后,您将能够:
使用 Nsight Systems 命令行分析器 (nsys ) 分析被加速的应用程序的性能。 利用对流多处理器 的理解优化执行配置。 理解统一内存 在页错误和数据迁移方面的行为。 使用异步内存预取 减少页错误和数据迁移以提高性能。 采用循环式的迭代开发加快应用程序的优化加速和部署。 使用 nsys 性能分析器帮助应用程序迭代地进行优化 如要确保优化加速代码库的尝试真正取得成功,唯一方法便是分析应用程序以获取有关其性能的定量信息。nsys 是指 NVIDIA 的 Nsight System 命令行分析器。该分析器附带于 CUDA 工具包中,提供分析被加速的应用程序性能的强大功能。
nsys 使用起来十分简单,最基本用法是向其传递使用 nvcc 编译的可执行文件的路径。随后 nsys 会继续执行应用程序,并在此之后打印应用程序 GPU 活动的摘要输出、CUDA API 调用以及统一内存 活动的相关信息。我们稍后会在本实验中详细介绍这一主题。
在加速应用程序或优化已经加速的应用程序时,我们应该采用科学的迭代方法。作出更改后需分析应用程序、做好记录并记录任何重构可能会对性能造成何种影响。尽早且经常进行此类观察通常会让您轻松获得足够的性能提升,以助您发布加速应用程序。此外,经常分析应用程序将使您了解到对 CUDA 代码库作出的特定更改会对其实际性能造成何种影响:而当只在代码库中进行多种更改后再分析应用程序时,将很难得知这一点。
nsys profile将生成一个qdrep报告文件,该文件可以以多种方式使用。 我们在这里使用--stats = true标志表示我们希望打印输出摘要统计信息。 输出的信息有很多,包括:
配置文件配置详细信息 报告文件的生成详细信息 CUDA API 统计信息 CUDA 核函数的统计信息 CUDA 内存操作统计信息(时间和大小) 操作系统内核调用接口的统计信息 值得一提的是,默认情况下,nsys profile不会覆盖现有的报告文件。 这样做是为了防止在进行概要分析时意外丢失工作。 如果出于某种原因,您宁愿覆盖现有的报告文件,例如在快速迭代期间,可以向nsys profile提供-f标志以允许覆盖现有的报告文件。
练习
优化前01-vector-add.cu
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 #include <stdio.h> void initWith (float num, float *a, int N) for (int i = 0 ; i < N; ++i)__global__ void addVectorsInto (float *result, float *a, float *b, int N) int index = threadIdx.x + blockIdx.x * blockDim.x;int stride = blockDim.x * gridDim.x;for (int i = index; i < N; i += stride)void checkElementsAre (float target, float *vector, int N) for (int i = 0 ; i < N; i++)if (vector[i] != target)printf ("FAIL: vector[%d] - %0.0f does not equal %0.0f\n" , i, vector[i], target);exit (1 );printf ("Success! All values calculated correctly.\n" );int main () const int N = 2 <<24 ;size_t size = N * sizeof (float );float *a;float *b;float *c;cudaMallocManaged (&a, size);cudaMallocManaged (&b, size);cudaMallocManaged (&c, size);initWith (3 , a, N);initWith (4 , b, N);initWith (0 , c, N);size_t threadsPerBlock;size_t numberOfBlocks;1 ;1 ;cudaGetLastError ();if (addVectorsErr != cudaSuccess) printf ("Error: %s\n" , cudaGetErrorString (addVectorsErr));cudaDeviceSynchronize ();if (asyncErr != cudaSuccess) printf ("Error: %s\n" , cudaGetErrorString (asyncErr));checkElementsAre (7 , c, N);cudaFree (a);cudaFree (b);cudaFree (c);
优化将 77 行的的 threadsPerblock 改为 1024 即可,分析可得核函数运行时间加快了一个量级,此外 cudaDeviceSynchronize()运行时间也大幅缩短,易于理解。
流多处理器(Streaming Multiprocessors)及查询 GPU 的设备配置 流多处理器和 Warps 运行 CUDA 应用程序的 GPU 具有称为流多处理器 (或 SM )的处理单元。在核函数执行期间,将线程块提供给 SM 以供其执行。为支持 GPU 执行尽可能多的并行操作,您通常可以选择线程块数量数倍于指定 GPU 上 SM 数量的网格大小 来提升性能。(提高 SM 的利用率)
此外,SM 会在一个名为warp 的线程块内创建、管理、调度和执行包含 32 个线程的线程组。值得注意的是,可以分配数量数倍于 32 的线程数量 来提升性能。
以编程方式查询 GPU 设备属性 由于 GPU 上的 SM 数量会因所用的特定 GPU 而异,因此为支持可移植性,您不得将 SM 数量硬编码到代码库中。相反,应该以编程方式获取此信息。
以下所示为在 CUDA C/C++ 中获取 C 结构的方法,该结构包含当前处于活动状态的 GPU 设备的多个属性,其中包括设备的 SM 数量:
1 2 3 4 5 6 int deviceId;cudaGetDevice (&deviceId); cudaGetDeviceProperties (&props, deviceId);
查询设备信息 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 #include <stdio.h> int main () int deviceId;cudaGetDevice (&deviceId);cudaGetDeviceProperties (&props, deviceId);int computeCapabilityMajor = props.major;int computeCapabilityMinor = props.minor;int multiProcessorCount = props.multiProcessorCount;int warpSize = props.warpSize;printf ("Device ID: %d\nNumber of SMs: %d\nCompute Capability Major: %d\nCompute Capability Minor: %d\nWarp Size: %d\n" , deviceId, multiProcessorCount, computeCapabilityMajor, computeCapabilityMinor, warpSize);
运行结果样式下图
Compute Capability Major(计算能力主版本): 这是主要版本号,表示 GPU 架构的主要特性。较新的主要版本通常支持更多的功能和性能提升。例如,Compute Capability Major 7 表示该 GPU 属于较新的架构。Compute Capability Minor(计算能力次版本): 这是次要版本号,表示 GPU 架构的次要特性。通常,次要版本的提升表示一些较小的改进或优化。Compute Capability Minor 5 表示该 GPU 的次要版本。将网格数调整为 SM 数,进一步优化矢量加法 得知设备信息后,对执行配置进行调整,对 01-vector-add.cu 进一步优化。
线程块调整为 80,线程数调成为 640,重复多次运行分析,核函数运行时间约在 0.12s 左右,相比优化前的 2.35s,以及上文的优化结果 0.145s,有了不小的进步。
获得统一内存的细节 统一内存(UM)的迁移 分配 UM 时,内存尚未驻留在主机或设备上。主机或设备尝试访问内存时会发生 页错误 ,此时主机或设备会批量迁移所需的数据。同理,当 CPU 或加速系统中的任何 GPU 尝试访问尚未驻留在其上的内存时,会发生页错误并触发迁移。
能够执行页错误并按需迁移内存对于在加速应用程序中简化开发流程大有助益。此外,在处理展示稀疏访问模式的数据时(例如,在应用程序实际运行之前无法得知需要处理的数据时),以及在具有多个 GPU 的加速系统中,数据可能由多个 GPU 设备访问时,按需迁移内存将会带来显著优势。
有些情况下(例如,在运行时之前需要得知数据,以及需要大量连续的内存块时),我们还能有效规避页错误和按需数据迁移所产生的开销。
本实验的后续内容将侧重于对按需迁移的理解,以及如何在分析器输出中识别按需迁移。这些知识可让您在享受按需迁移优势的同时,减少其产生的开销。
练习:探索统一内存(UM)的页错误 nsys profile 会提供描述所分析应用程序 UM 行为的输出。在本练习中,您将对一个简单的应用程序做出一些修改,并会在每次更改后利用 nsys profile 的统一内存输出部分,探讨 UM 数据迁移的行为方式。
01-page-faults.cuhostFunction 和 gpuKernel 函数,我们可以通过这两个函数并使用数字 1 初始化 2<<24 个单元向量的元素。主机函数和 GPU 核函数目前均未使用。
对于以下 4 个问题中的每一问题,请根据您对 UM 行为的理解,首先假设应会发生何种页错误,然后使用代码库中所提供 2 个函数中的其中一个或同时使用这两个函数编辑 01-page-faults.cu
为了检验您的假设,请使用下面的代码执行单元来编译和分析代码。 一定要记录从nsys profile --stats = true输出中获得的假设以及结果。 在nsys profile --stats = true的输出中,您应该查找以下内容:
输出中是否有 CUDA 内存操作统计信息 部分? 如果是,这是否表示数据从主机到设备(HtoD)或从设备到主机(DtoH)的迁移? 进行迁移时,输出如何说明有多少个“操作”? 如果看到许多小的内存迁移操作,则表明按需出现页面错误,并且每次在请求的位置出现页面错误时都会发生小内存迁移。 以下是供您探索的方案,以及遇到困难时的解决方案:
当仅通过 CPU 访问统一内存时,是否存在内存迁移和/或页面错误的证据? 当仅通过 GPU 访问统一内存时,是否有证据表明内存迁移和/或页面错误? 当先由 CPU 然后由 GPU 访问统一内存时,是否有证据表明存在内存迁移和/或页面错误? 当先由 GPU 然后由 CPU 访问统一内存时,是否存在内存迁移和/或页面错误的证据?
上图为nsys profile --stats = true输出内容中显示的数据从设备到主机的迁移 DtoH,总操作数为 768,可以看到有许多小内存的迁移操作,验证了按需出现页面错误,并且每次在请求的位置出现页面错误时都会发生小内存迁移。
当 nsys profile 给出核函数所需的执行时间时,则在此函数执行期间发生的主机到设备页错误和数据迁移都会包含在所显示的执行时间中。故可以通过减少 UM 页错误和数据迁移的发生缩短核函数运行时间。
异步内存预取 在主机到设备和设备到主机的内存传输过程中,我们使用一种技术来减少页错误和按需内存迁移成本,此强大技术称为异步内存预取 。通过此技术,程序员可以在应用程序代码使用统一内存 (UM) 之前,在后台将其异步迁移至系统中的任何 CPU 或 GPU 设备。此举可以减少页错误和按需数据迁移所带来的成本,并进而提高 GPU 核函数和 CPU 函数的性能。
此外,预取往往会以更大的数据块来迁移数据,因此其迁移次数要低于按需迁移。此技术非常适用于以下情况:在运行时之前已知数据访问需求且数据访问并未采用稀疏模式。
CUDA 可通过 cudaMemPrefetchAsync 函数,轻松将托管内存异步预取到 GPU 设备或 CPU。以下所示为如何使用该函数将数据预取到当前处于活动状态的 GPU 设备,然后再预取到 CPU:
1 2 3 4 5 int deviceId;cudaGetDevice (&deviceId); cudaMemPrefetchAsync (pointerToSomeUMData, size, deviceId);cudaMemPrefetchAsync (pointerToSomeUMData, size, cudaCpuDeviceId);
练习:异步内存预取 在 01-vector-add.cu 应用程序中使用 cudaMemPrefetchAsync 函数开展 实验,以探究其会对页错误和内存迁移产生何种影响。
结果:可以看到内存传输次数减少了,但是每次传输的量增加了,并且内核执行时间大大减少了。
异步流及 CUDA C/C++ 应用程序的可视化性能分析 CUDA 工具包附带了 Nsight Systems ,这是一个功能强大的 GUI 应用程序,可支持 CUDA 应用程序的开发。 Nsight Systems 为被加速的应用程序生成图形化的活动时间表,其中包含有关 CUDA API 调用、内核执行、内存活动以及CUDA 流 的使用的详细信息。
学习目标 在完成本练习后,您将能够:
使用Nsight Systems 直观地描述由 GPU 加速的 CUDA 应用程序的时间表。 使用Nsight Systems 识别和利用 CUDA 应用程序中的优化机会。 利用 CUDA 流在被加速的应用程序中并发执行核函数。 ( 可选的进阶内容 )使用手动的设备内存分配,包括分配固定的内存,以便在并发 CUDA 流之间异步传输数据。 运行 Nsight Systems 此处使用的是英伟达配置好的远程桌面,可以直接启动和使用 Nsight Systems(但是无比的卡顿),建议在本地配置,进行可视化分析。
主要对前面的各种优化进行可视化分析,故不做记录
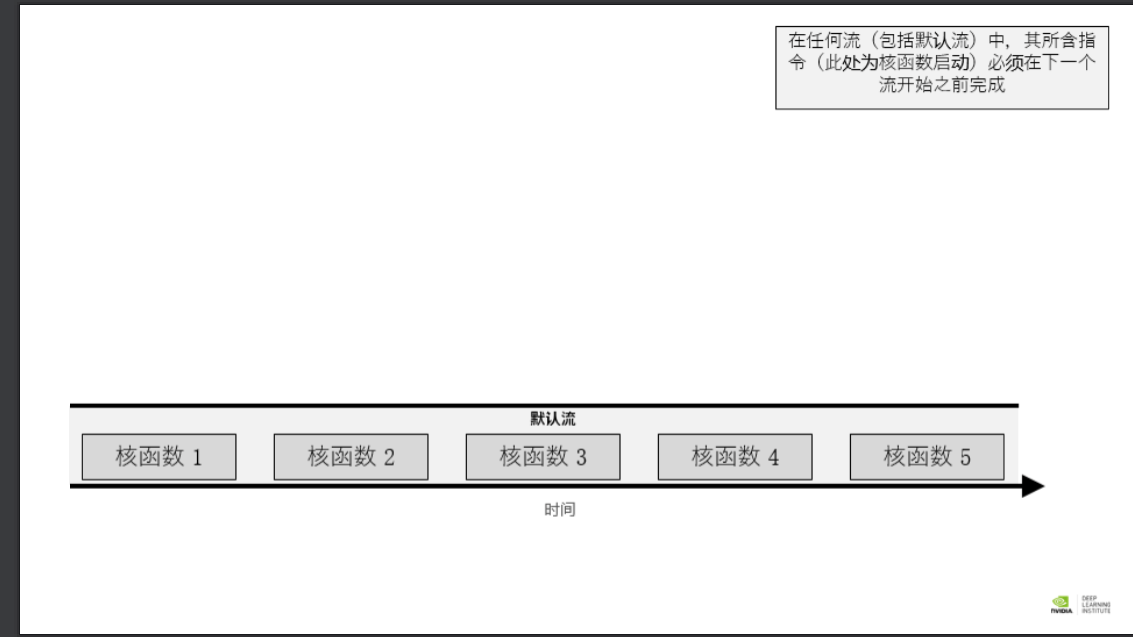
并发 CUDA 流 在 CUDA 编程中,流 是由按顺序执行的一系列命令构成。在 CUDA 应用程序中,核函数的执行以及一些内存传输均在 CUDA 流中进行。不过直至此时,您仍未直接与 CUDA 流打交道;但实际上您的 CUDA 代码已在名为默认流 的流中执行了其核函数。
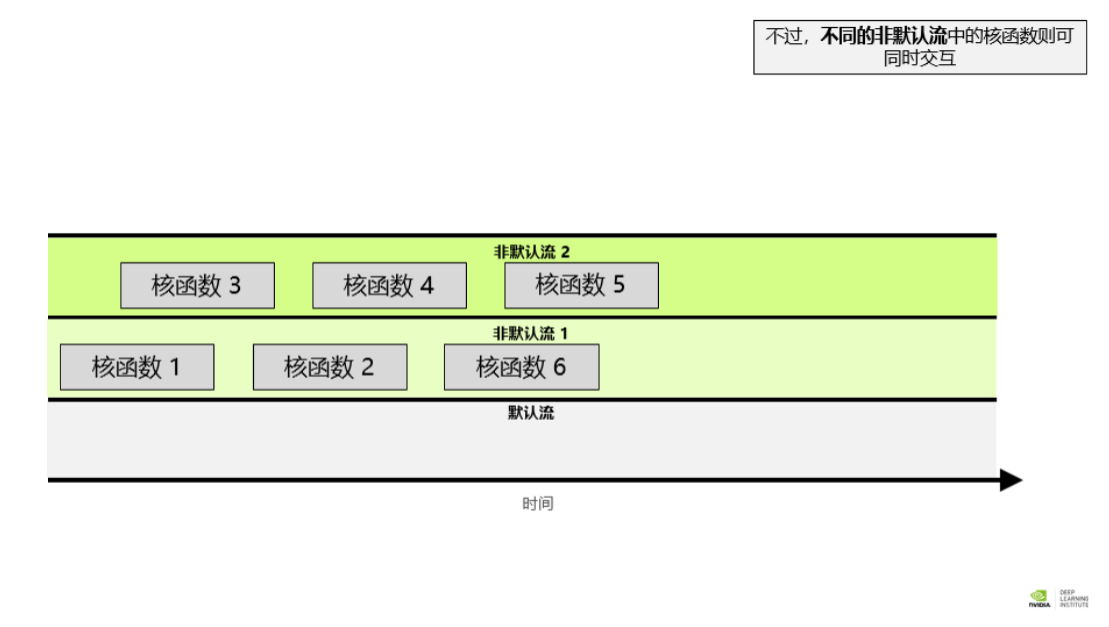
除默认流以外,CUDA 程序员还可创建并使用非默认 CUDA 流,此举可支持执行多个操作,例如在不同的流中并发执行多个核函数。多流的使用可以为您的加速应用程序带来另外一个层次的并行,并能提供更多应用程序的优化机会。
以下为默认流和非默认流的关系
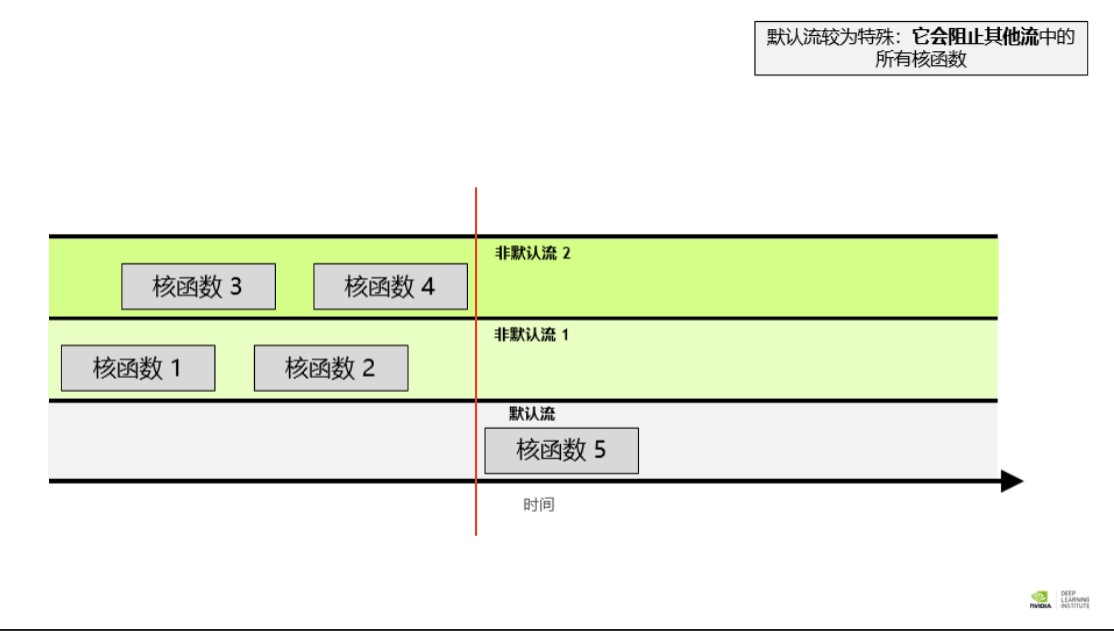
就不同非默认流中的操作而言,无法保证其会按彼此之间的任何特定顺序执行。 默认流具有阻断能力,即,它会等待其它已在运行的所有流完成当前操作之后才运行,但在其自身运行完毕之前亦会阻碍其它流的运行 创建,使用和销毁非默认 CUDA 流 以下代码段演示了如何创建,利用和销毁非默认 CUDA 流。您会注意到,要在非默认 CUDA 流中启动 CUDA 核函数,必须将流作为执行配置的第 4 个可选参数传递给该核函数。到目前为止,您仅利用了执行配置的前两个参数:
1 2 3 4 5 6 cudaStream_t stream; cudaStreamCreate (&stream); 0 , stream>>>(); cudaStreamDestroy (stream);
但值得一提的是,执行配置的第 3 个可选参数超出了本实验的范围。此参数允许程序员提供共享内存 中为每个内核启动动态分配的字节数。每个块分配给共享内存的默认字节数为“0”,在本练习的其余部分中,您将传递“ 0”作为该值,以便展示我们感兴趣的第 4 个参数。
练习 源程序
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 #include <stdio.h> __global__ void printNumber (int number) printf ("%d\n" , number);int main () for (int i = 0 ; i < 5 ; ++i)1 , 1 >>>(i);cudaDeviceSynchronize ();
可以预见核函数的 5 次启动都在默认流顺次执行,可以用 Nsight Systems 进行可视化分析。由于核函数的所有 5 次启动均在同一个流中发生,因此看到 5 个核函数顺次执行也就不足为奇。此外,也可以这么说,由于默认流具有阻断作用,所以核函数都会在完成本次启动之后才启动下一次,而事实也是如此。
重构
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 #include <stdio.h> #include <unistd.h> __global__ void printNumber (int number) printf ("%d\n" , number);int main () for (int i = 0 ; i < 5 ; ++i)cudaStreamCreate (&stream);1 , 1 , 0 , stream>>>(i);cudaStreamDestroy (stream);cudaDeviceSynchronize ();
原程序
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 #include <stdio.h> __global__ void initWith (float num, float *a, int N) int index = threadIdx.x + blockIdx.x * blockDim.x;int stride = blockDim.x * gridDim.x;for (int i = index; i < N; i += stride)__global__ void addVectorsInto (float *result, float *a, float *b, int N) int index = threadIdx.x + blockIdx.x * blockDim.x;int stride = blockDim.x * gridDim.x;for (int i = index; i < N; i += stride)void checkElementsAre (float target, float *vector, int N) for (int i = 0 ; i < N; i++)if (vector[i] != target)printf ("FAIL: vector[%d] - %0.0f does not equal %0.0f\n" , i, vector[i], target);exit (1 );printf ("Success! All values calculated correctly.\n" );int main () int deviceId;int numberOfSMs;cudaGetDevice (&deviceId);cudaDeviceGetAttribute (&numberOfSMs, cudaDevAttrMultiProcessorCount, deviceId);const int N = 2 <<24 ;size_t size = N * sizeof (float );float *a;float *b;float *c;cudaMallocManaged (&a, size);cudaMallocManaged (&b, size);cudaMallocManaged (&c, size);cudaMemPrefetchAsync (a, size, deviceId);cudaMemPrefetchAsync (b, size, deviceId);cudaMemPrefetchAsync (c, size, deviceId);size_t threadsPerBlock;size_t numberOfBlocks;256 ;32 * numberOfSMs;3 , a, N);4 , b, N);0 , c, N);cudaGetLastError ();if (addVectorsErr != cudaSuccess) printf ("Error: %s\n" , cudaGetErrorString (addVectorsErr));cudaDeviceSynchronize ();if (asyncErr != cudaSuccess) printf ("Error: %s\n" , cudaGetErrorString (asyncErr));cudaMemPrefetchAsync (c, size, cudaCpuDeviceId);checkElementsAre (7 , c, N);cudaFree (a);cudaFree (b);cudaFree (c);
重构
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 #include <stdio.h> __global__ void initWith (float num, float *a, int N) int index = threadIdx.x + blockIdx.x * blockDim.x;int stride = blockDim.x * gridDim.x;for (int i = index; i < N; i += stride)__global__ void addVectorsInto (float *result, float *a, float *b, int N) int index = threadIdx.x + blockIdx.x * blockDim.x;int stride = blockDim.x * gridDim.x;for (int i = index; i < N; i += stride)void checkElementsAre (float target, float *vector, int N) for (int i = 0 ; i < N; i++)if (vector[i] != target)printf ("FAIL: vector[%d] - %0.0f does not equal %0.0f\n" , i, vector[i], target);exit (1 );printf ("Success! All values calculated correctly.\n" );int main () int deviceId;int numberOfSMs;cudaGetDevice (&deviceId);cudaDeviceGetAttribute (&numberOfSMs, cudaDevAttrMultiProcessorCount, deviceId);const int N = 2 <<24 ;size_t size = N * sizeof (float );float *a;float *b;float *c;cudaMallocManaged (&a, size);cudaMallocManaged (&b, size);cudaMallocManaged (&c, size);cudaMemPrefetchAsync (a, size, deviceId);cudaMemPrefetchAsync (b, size, deviceId);cudaMemPrefetchAsync (c, size, deviceId);size_t threadsPerBlock;size_t numberOfBlocks;256 ;32 * numberOfSMs;cudaStreamCreate (&stream1);cudaStreamCreate (&stream2);cudaStreamCreate (&stream3);0 , stream1>>>(3 , a, N);0 , stream2>>>(4 , b, N);0 , stream3>>>(0 , c, N);cudaGetLastError ();if (addVectorsErr != cudaSuccess) printf ("Error: %s\n" , cudaGetErrorString (addVectorsErr));cudaDeviceSynchronize ();if (asyncErr != cudaSuccess) printf ("Error: %s\n" , cudaGetErrorString (asyncErr));cudaMemPrefetchAsync (c, size, cudaCpuDeviceId);checkElementsAre (7 , c, N);cudaStreamDestroy (stream1);cudaStreamDestroy (stream2);cudaStreamDestroy (stream3);cudaFree (a);cudaFree (b);cudaFree (c);
最终任务:加速和优化 N 体模拟器 n-body 模拟器可以预测通过引力相互作用的一组物体的个体运动。01-nbody.cu 包含一个简单而有效的 n-body 模拟器,适合用于在三维空间移动的物体。我们可通过向该应用程序传递一个命令行参数以影响系统中的物体数量。
以目前的仅用 CPU 的情况下,此应用程序大约需要 5 秒钟才能运行 4096 个物体,需要20 分钟 才能运行 65536 个物体。您的任务是用 GPU 加速程序,同时保持仿真的正确性。
源程序如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 #include <math.h> #include <stdio.h> #include <stdlib.h> #include "timer.h" #include "files.h" #define SOFTENING 1e-9f typedef struct { float x, y, z, vx, vy, vz; } Body;void bodyForce (Body *p, float dt, int n) for (int i = 0 ; i < n; ++i) {float Fx = 0.0f ; float Fy = 0.0f ; float Fz = 0.0f ;for (int j = 0 ; j < n; j++) {float dx = p[j].x - p[i].x;float dy = p[j].y - p[i].y;float dz = p[j].z - p[i].z;float distSqr = dx*dx + dy*dy + dz*dz + SOFTENING;float invDist = rsqrtf (distSqr);float invDist3 = invDist * invDist * invDist;int main (const int argc, const char ** argv) int nBodies = 2 <<11 ;if (argc > 1 ) nBodies = 2 <<atoi (argv[1 ]);const char * initialized_values;const char * solution_values;if (nBodies == 2 <<11 ) {"files/initialized_4096" ;"files/solution_4096" ;else { "files/initialized_65536" ;"files/solution_65536" ;if (argc > 2 ) initialized_values = argv[2 ];if (argc > 3 ) solution_values = argv[3 ];const float dt = 0.01f ; const int nIters = 10 ; int bytes = nBodies * sizeof (Body);float *buf;float *)malloc (bytes);read_values_from_file (initialized_values, buf, bytes);double totalTime = 0.0 ;for (int iter = 0 ; iter < nIters; iter++) {StartTimer ();bodyForce (p, dt, nBodies); for (int i = 0 ; i < nBodies; i++) { const double tElapsed = GetTimer () / 1000.0 ;double avgTime = totalTime / (double )(nIters);float billionsOfOpsPerSecond = 1e-9 * nBodies * nBodies / avgTime;write_values_to_file (solution_values, buf, bytes);printf ("%0.3f Billion Interactions / second" , billionsOfOpsPerSecond);free (buf);
优化热点如下:
将 bodyforce 函数改为核函数,外层循环可以优化,内层循环具有顺序依赖故不做改动 将 bodyforce 函数执行后的将引力集成到各物体位置的 for 循环改为核函数。“该集成不仅需在 bodyForce 函数运行后进行,并且需在下一次调用 bodyForce 函数之前完成。”所以,在执行前添加 cudaDeviceSynchronize()语句 执行配置根据 SMs 和 wraps 数量进行配置(此处线程数越大,核函数运行时间反而变长,取 32 和 64 的运行时间相对较优) 重构结果
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 #include <math.h> #include <stdio.h> #include <stdlib.h> #include "timer.h" #include "files.h" #define SOFTENING 1e-9f typedef struct { float x, y, z, vx, vy, vz; } Body;__global__ void bodyForce (Body *p, float dt, int n) {int index = threadIdx.x + blockIdx.x * blockDim.x;int stride = blockDim.x * gridDim.x;for (int i = index; i < n; i += stride){float Fx = 0.0f ; float Fy = 0.0f ; float Fz = 0.0f ;for (int j = 0 ; j < n; j++) {float dx = p[j].x - p[i].x;float dy = p[j].y - p[i].y;float dz = p[j].z - p[i].z;float distSqr = dx*dx + dy*dy + dz*dz + SOFTENING;float invDist = rsqrtf (distSqr);float invDist3 = invDist * invDist * invDist;__global__ void integrate_position (Body *p,float dt,int n) {int index = threadIdx.x + blockIdx.x * blockDim.x;int stride = blockDim.x * gridDim.x;for (int i = index; i < n; i += stride) {int main (const int argc, const char ** argv) int deviceId;int numberOfSMs;cudaGetDevice (&deviceId);cudaDeviceGetAttribute (&numberOfSMs, cudaDevAttrMultiProcessorCount, deviceId);int nBodies = 2 <<11 ;if (argc > 1 ) nBodies = 2 <<atoi (argv[1 ]);const char * initialized_values;const char * solution_values;if (nBodies == 2 <<11 ) {"files/initialized_4096" ;"files/solution_4096" ;else { "files/initialized_65536" ;"files/solution_65536" ;if (argc > 2 ) initialized_values = argv[2 ];if (argc > 3 ) solution_values = argv[3 ];const float dt = 0.01f ; const int nIters = 10 ; int bytes = nBodies * sizeof (Body);float *buf;cudaMallocManaged (&buf, bytes);size_t threadsPerBlock = 64 ;size_t numberOfBlocks = 32 * numberOfSMs;read_values_from_file (initialized_values, buf, bytes);double totalTime = 0.0 ;for (int iter = 0 ; iter < nIters; iter++) {StartTimer ();cudaDeviceSynchronize ();const double tElapsed = GetTimer () / 1000.0 ;double avgTime = totalTime / (double )(nIters);float billionsOfOpsPerSecond = 1e-9 * nBodies * nBodies / avgTime;write_values_to_file (solution_values, buf, bytes);printf ("%0.3f Billion Interactions / second" , billionsOfOpsPerSecond);cudaFree (buf);
最后优化结果,计算 4096 个物体
1 2 您的应用程序运行了: 0.1543秒
计算 65536 个物体
1 2 您的应用程序运行了: 0.4912秒
建议结合可视化分析,也许可以得到更优的结果。(本人由于懒得部署本地 Nsight Systems,且英伟达提供的远程桌面过于卡顿,故没有结合可视化分析。虽然尝试了异步内存预取和使用非默认流,但是效果并不显著,因为没法进行可视化分析,我也不清楚内存转移时间是否缩短和不同非默认流是否并行,所以使用可视化分析,可能可以进行进一步的优化)
小结 姑且算是接触了 cuda c 编程的皮毛。缘由是上学期心头一热选的公选课,但由于要跨校区上课,所以也没去过几节课(别问,就是懒)。没退课的原因主要是想在 cuda 上加半个技能点,而且这是学校帮忙兑换的 Nvidia 线上自主培训课程,价值 89 刀,薅一手。
平时没学,为了完成大作业,就在这几周速通了,学习记录在这篇 blog。此外由于课上运行都是在英伟达提供的远程云环境中,没有考虑到配置 cuda 环境的诸多麻烦。上周速成大作业的时候,跌跌撞撞地配了快一天的环境 😅,如果后面有想法,打算再写篇博客记录下环境配置。
——2023 年倒数第三天的晚上。